유튜브 등을 통해 공유되는 미국 현지의 테슬라 FSD(Full Self-Driving) V14 주행 영상은 단순한 주행 보조 장치의 업데이트 수준이 아님.
비보호 좌회전을 부드럽게 넘기고 돌발적인 자전거를 회피하며, 복잡한 공사 구역을 자연스럽게 통과하는 모습은 인간의 논리적 개입이 배제된 인공지능의 주행을 보여줌.
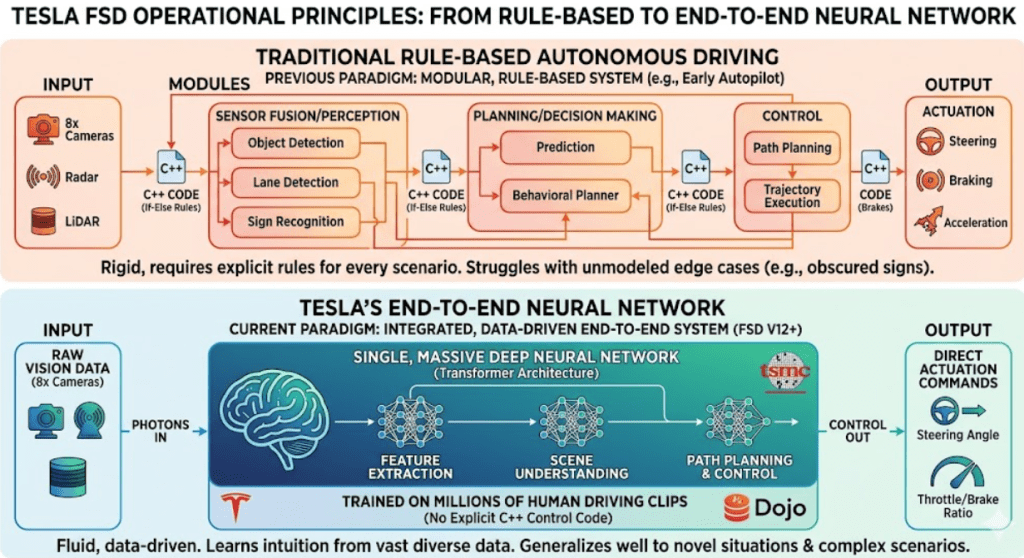
이는 기존 자율주행의 핵심이었던 수십만 줄의 조건문(If-Else) 코드를 폐기하고, 오직 비디오 데이터로 현실 세계의 물리 법칙을 학습하는 ‘엔드투엔드(End-to-End) 신경망’을 도로에 적용한 결과임.
레거시 완성차 업체들이 센서 개수 늘리기에 집중할 때, 테슬라는 반도체 전성비 극대화와 슈퍼컴퓨터 생태계 구축을 통해 소프트웨어 아키텍처의 초격차를 만들어냈음.
수십만 줄의 C++ 코드를 불태우다: 엔드투엔드(End-to-End)의 혁명
기존 오토파일럿이나 타 업체의 자율주행 기술은 모듈화된 ‘규칙 기반(Rule-based)’ 시스템임.
엔지니어들이 “정지 표지판이 보이면 브레이크를 밟는다”는 식으로 상황을 하드코딩했기 때문에, 센서가 오염되거나 인식 범위를 벗어난 예외 상황이 발생하면 시스템 오류로 이어짐.
반면 테슬라는 FSD V12부터 이 방식을 단일 신경망으로 전면 교체했음.
- 모듈화의 전면 폐기: 차선 인식, 장애물 분류, 속도 제어를 따로 나누던 기존 아키텍처를 완전히 배제함.
- 직관적 제어 매커니즘: 카메라 렌즈를 통과한 빛(Photon) 데이터가 입력층으로 들어오면 인간의 논리 개입 없이 AI가 조향각과 페달 비율(Output)이라는 제어 신호를 즉각 뱉어냄.
- 직관적 통째 학습: 어린아이가 수없이 넘어지며 자전거 타는 법을 몸으로 배우듯, 수백만 대의 차량이 수집한 ‘베스트 인간 드라이빙 영상’ 토큰을 거대 신경망에 그대로 먹여 AI가 스스로 운전 감각을 터득함.
- 초저지연 추론 능력: 시속 100km로 달리는 차 안에서 8대의 카메라가 초당 36프레임씩 쏟아내는 고해상도 영상을 단 몇 밀리초(ms) 만에 딜레이 없이 분석하여 스티어링 휠과 브레이크를 제어함.
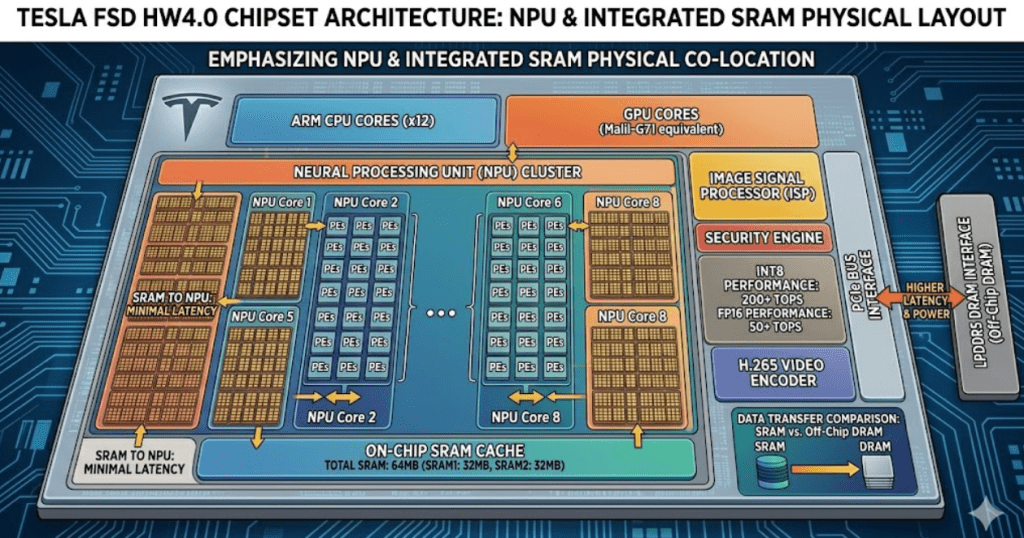
‘Photon in, Control out’을 구현하는 FSD 하드웨어의 미친 전성비
카메라 렌즈를 통과한 빛(Photon) 데이터가 중간 인지/판단 모듈 없이, 인공지능의 연산만으로 핸들 조향과 페달 제어(Control out) 결과값으로 즉각 변환됨.
수백만 대의 차량이 모은 베스트 드라이빙 토큰을 통째로 학습하여, 어린아이가 자전거 타는 법을 몸으로 익히듯 AI가 스스로 운전 감각을 터득한 것임.
도로 위 수많은 테슬라가 매 순간 수집하는 코너 케이스(예외 상황) 영상들이 텍사스 기가팩토리 도조 서버로 전송되어 모델을 24시간 무한 재학습시키는 데이터 플라이휠이 작동하고 있음.
기존 오토파일럿(Rule-based) vs 테슬라 FSD V14(End-to-End) 완벽 비교
도대체 차 안의 컴퓨터에서 어떤 미친 연산이 일어나길래 이토록 차원이 다른 주행이 가능한지, 반도체 현업 엔지니어 관점에서 칩과 아키텍처의 상세 스펙을 표로 알아보겠음.
| 비교 스펙 | 기존 오토파일럿 (Rule-based) | 테슬라 FSD V14 (End-to-End) |
| 제어 아키텍처 | 인지/판단/제어 모듈 분리형 (인간 엔지니어 코딩 의존) | 단일 거대 인공지능 신경망 (비전 데이터가 물리 제어로 직결) |
| 핵심 반도체 칩 | HW3 (기본적인 영상 처리 및 제한적인 NPU 성능) | HW4 및 차세대 AI5 (극한 NPU 성능 탑재) |
| 메모리 병목 해결 | 외부 D램 의존도 높음 (데이터 전송 시 속도 저하 및 전력 소모 큼) | 연산기(MAC) 옆 거대 용량의 SRAM 캐시를 때려 박아 지연 제로 |
| 연산 처리 방식 | 부동소수점 정밀도 위주의 무겁고 느린 연산 구조 | INT8(정수 연산) 극대화로 추론(Inference) 처리량 비약적 펌핑 |
| 예외 상황 대처 | 코딩되지 않은 변수(비에 젖은 표지판, 찌그러진 가드레일) 등장 시 에러 | 수천만 시간의 영상 데이터 학습을 통해 본능적이고 유연하게 스르륵 대처 |
| AI 학습 인프라 | 개발자가 수동으로 개별 주행 데이터를 라벨링하는 노가다 작업 | 엑사플롭스(Exaflops)급 도조 슈퍼컴퓨터 생태계의 스케일링 법칙 적용 |
자동차라는 제한된 폼팩터 안에서 거대한 AI 모델을 돌리는 것은 결국 ‘발열’과 ‘전력 대비 성능(전성비)’의 싸움임.
테슬라는 전력 소모가 큰 범용 GPU를 억지로 탑재하는 대신, 고용량 SRAM을 NPU에 극단적으로 집적시킨 맞춤형 반도체를 설계해 하드웨어 병목 현상(Bottleneck)을 원천 차단했음.
시속 100km로 달리는 차 안에서 8대의 카메라가 초당 36프레임씩 쏟아내는 고해상도 영상을 단 몇 밀리초(ms) 만에 딜레이 없이 분석할 수 있는 이유가 바로 이 아키텍처 최적화에 있음.
레거시 완성차들이 부러워하는 FSD의 차별화 포인트
기술의 근본을 파악하기 위한 FAQ
Q1. 내가 매일 타는 오토파일럿 차량도 무선 업데이트만 계속 받으면 FSD처럼 똑똑해질 수 있나?
A1. 그렇지 않음. 오토파일럿과 FSD는 뇌를 구성하는 근본 아키텍처 자체가 윈도우와 맥OS만큼 완전히 다름. 톨게이트만 나오면 차선을 잃고 버벅거리는 오토파일럿은 규칙 기반 시스템의 한계임. FSD 소프트웨어 별도 구매는 물론이고, 최신 하드웨어 성능이 뒷받침되지 않으면 죽었다 깨어나도 미국 영상 속의 마법 같은 도심 자율주행은 불가능함.
Q2. 왜 테슬라는 그 좋다는 엔비디아 칩을 버리고 무모하게 자체 칩 설계를 고집하나?
A2. 전기차는 배터리에 목숨을 거는 ‘움직이는 전력 제한 구역’이기 때문임. 엔비디아의 거대 GPU는 성능은 훌륭하지만 차에 달기엔 전력 소모와 발열이 도를 넘었음. 테슬라는 데이터를 외부 메모리에서 끌어올 때 생기는 전력 낭비와 딜레이를 막기 위해, 연산기 바로 옆에 비싼 SRAM을 가득 채워 넣은 독자 칩을 개발해 초저전력 초고속 추론 환경을 강제로 구축한 것임.
Q3. 독일 3사나 다른 레거시 업체들이 비싼 라이다(LiDAR) 센서 엄청 달고 나오면 결국 테슬라 잡는 거 아님?
A3. 하드웨어 스펙 경쟁만 생각했을 때 나올 수 있는 질문이라고 생각함. 미래 자율주행 기술의 격차는 센서 개수가 아니라, 누가 더 많은 컴퓨팅 자원을 쏟아붓고 더 압도적인 양의 ‘비디오 토큰’을 먹이느냐의 스케일링 법칙(Scaling Laws)에 달렸음. 다른 완성차 업체들이 테스트카 몇백 대 돌리면서 자화자찬할 때, 테슬라는 전 세계 도로를 누비는 수백만 대의 고객 차량에서 가장 가치 있는 ‘실패 및 개입 영상’만을 진공청소기처럼 빨아들여 모델을 진화시키고 있음. 생태계 싸움에서 이미 승부가 났다고 생각.
현재 테슬라 FSD가 입증하고 있는 주행 성능은 차량 내부에 탑재된 칩 하나만으로 완성된 결과가 아님.
거대한 슈퍼컴퓨터 클러스터가 막대한 비디오 데이터를 지속적으로 소화하며 인공지능 모델의 크기를 키우는 ‘스케일링 생태계’가 구축되었기 때문임.
전력망이 극도로 제한된 자동차에서 무거운 신경망을 실시간으로 구동하기 위해 SRAM 집적도를 극대화한 FSD 칩 설계는 반도체 공학적으로도 고도의 최적화 결과물임.
결과적으로, 수십만 줄의 코드를 만지며 조건문을 덧붙여 나가는 기존의 기술력으로는 현실 세계의 물리 법칙을 통째로 학습한 엔드투엔드 AI의 발전 속도를 따라잡기 매우 어려울 것으로 분석됨.
(※ 본 글은 작성일 기준의 데이터와 개인적 분석을 바탕으로 작성된 자율주행 기술력에 대한 글이며, 자산 추천에 대한 글이 아닙니다)