요즘 제미나이 3.1 Pro 같은 최신 AI 모델들이 ‘500만 토큰’을 지원하기 시작했음.
이게 왜 미친 거냐면, 예전처럼 텍스트를 조각조각 쪼개서 넣을 필요 없이 수만 줄짜리 장비 매뉴얼이나 에러 로그를 한 번에 때려 넣어도 전체 맥락을 다 알아먹는다는 뜻임. 바야흐로 ‘롱 컨텍스트(Long Context)’ 시대가 온 거임.
근데 소프트웨어가 이렇게 날아다녀도 마냥 좋아할 수 없는 이유가 있음. 결국 이 무지막지한 데이터를 처리하려면 하드웨어 쪽에서 메모리 대역폭 병목이 오지게 걸리기 때문임. 토큰 확장이 가져온 진짜 변화와, 왜 지금 반도체 시장이 HBM4에 혈안이 되어 있는지 핵심만 짚어봄.
500만 토큰 시대 : 정보 파편화(쪼개기)의 종말
AI랑 대화할 때 쓰는 단위인 ‘토큰’은 그냥 언어의 조각이라고 보면 됨.
초창기 챗GPT는 몇천 개 단위라 뭐 좀 길게 쓰면 앞부분 다 까먹었음. 근데 2026년 지금은 500만 개를 한 번에 씹어 먹음.
- 업무의 변화: 예전엔 수백 장짜리 매뉴얼에서 필요한 거 찾으려고 똥꼬쇼를 했다면, 이젠 그냥 통째로 던져주고 “여기서 에러 원인 찾아” 하면 끝남. 파편화된 정보 맞추느라 고생하던 짓거리가 사라진 거임.
- 실제 체감: 500만 토큰이면 책 수백 권, 며칠 치 영상 데이터를 한방에 넣는 수준임.
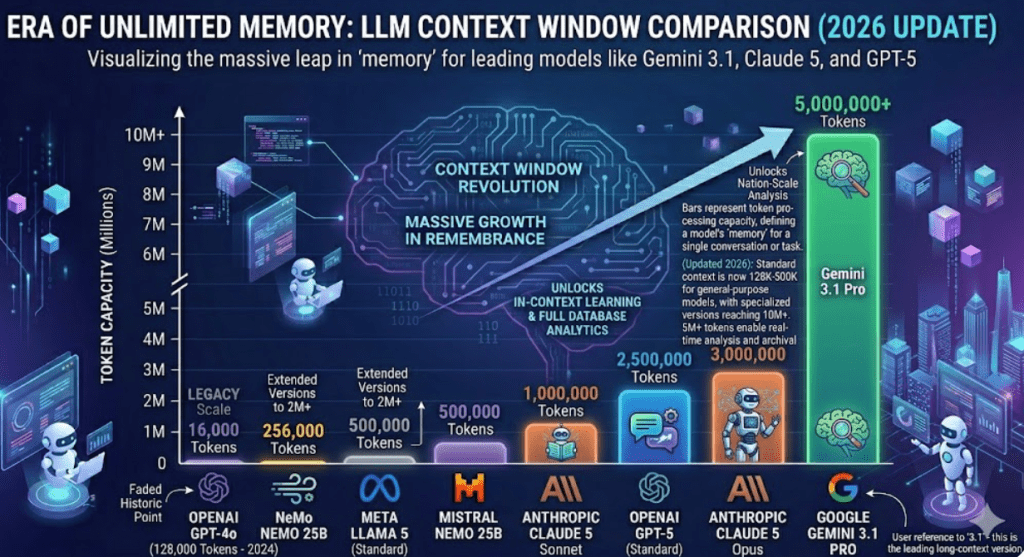
과거에는 AI가 앞서 했던 말을 금방 까먹거나, 긴 문서를 입력하면 뒷부분을 잘라먹는 일이 허다해서, “아 역시 AI는 무슨 한참 멀었구만” 했었는데, 이제는 ‘전체 맥락’을 한 번에 들여다 볼 수 있게 되었음. 이는 마치 돋보기를 들고 지도 여기저기를 살피던 사람이 헬기를 타고 지형 전체를 내려다보게 된 것과 같음. 데이터가 파편화되지 않고 하나의 거대한 맥락 속에서 해석되기 시작하면서, AI는 이제 단순한 비서가 아니라 복잡한 프로젝트를 함께 수행하는 ‘파트너’의 영역으로 진입했다는게 직접 체감이 되는 시대가 됨.
반도체 엔지니어 시선 : 결국 HBM4와 KV 캐시 싸움
소프트웨어가 이렇게 똑똑해지는 동안 하드웨어는 뒤에서 비명을 지르고 있음. 토큰이 늘어난다? 연산량 폭증 + 메모리 병목 확정임.
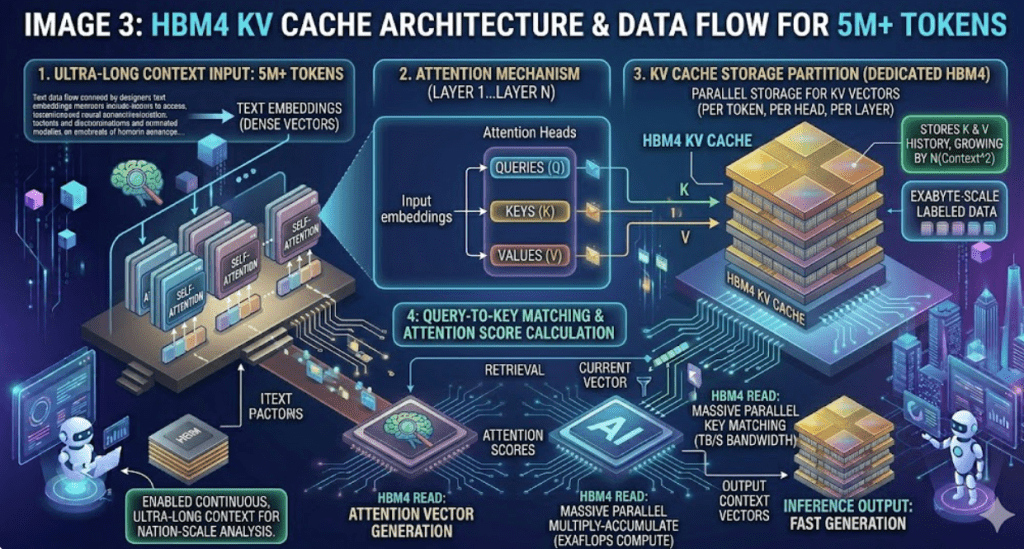
문제는 KV 캐시(Key-Value Cache) 용량 트랜스포머 아키텍처 특성상 토큰이 늘어나면 연산 능력이 기하급수적으로 필요해짐. 특히 AI가 대화 문맥을 임시로 기억해 두는 공간을 ‘KV 캐시’라고 부르는데, 500만 토큰을 처리하려면 이 캐시 용량이 어마어마하게 커져야 함.
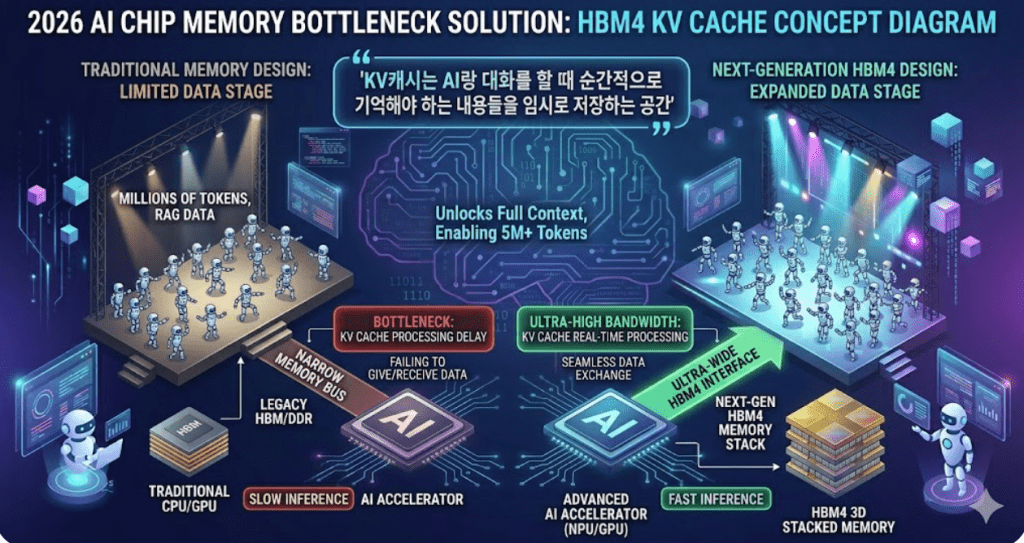
왜 HBM4가 필수인가? 기존 HBM3나 HBM3E로는 이 무지막지한 KV 캐시를 초고속으로 쏘고 받을 수가 없음. 억지로 돌리면 열풍기 틀어놓은 것마냥 열 나고 전력 오지게 퍼먹음. 결국 HBM4 고적층 기술로 이 병목을 뚫어줘야 AI 속도가 안 뒤처짐.
지금 반도체 회사들이 HBM4 주도권 잡으려고 피 터지게 싸우는 이유가, 결국 이 ‘거대한 데이터 무대’를 깔아주기 위해서임. 무대가 좁으면 데이터가 아무리 춤을 추고 싶어도 못 춤.
| 구분 | 2024년 (초기 AI) | 2026년 (현 시점) |
| 기본 토큰 용량 | 수만 개 수준 (단기 기억) | 500만 개 이상 (롱 컨텍스트) |
| 데이터 처리 | 문서를 쪼개서 입력 (파편화) | 수백 권의 책을 통째로 분석 |
| 메모리 기술 | HBM3 / HBM3E | HBM4 (KV 캐시 최적화) |
| 핵심 기술 | 단순 파인튜닝(Fine-tuning) | 고도화된 RAG 및 인컨텍스트 러닝 |
실제로 업무를 하다보면 이 하드웨어의 한계가 뼈아프게 다가옴. 500만 토큰을 실시간으로 추론하기 위해 칩 내부에서 발생하는 열과 전력 소모를 보고 있으면, “소프트웨어의 진화를 하드웨어가 겨우겨우 따라가고 있구나”라는 생각이 들기 때문. HBM4의 적층 수가 늘어날수록 공정 난이도는 점점 더 장난아니게 되는데, 이걸 해결하지 못하면 무한 토큰 시대의 속도는 반토막 날 수밖에 없음. 결국 이 전쟁은 누가 더 거대한 ‘데이터 무대’를 안정적으로 깔아주느냐의 싸움이 됨.
‘딸깍’의 시대: RAG와 인컨텍스트 러닝의 떡상
하드웨어가 받쳐줘서 무한 토큰이 돌아가기 시작하면, 비즈니스 판도는 완전히 바뀜. 검색 엔진 뒤적거리는 시대는 이미 끝났음.
멀티모달 짬뽕: 텍스트, 고화질 이미지, 깃허브 소스 코드 뭉탱이를 한 윈도우에 넣고 돌리면 생산성 수십 배 뛰는 건 시간문제임.
무거운 파인튜닝은 가라: 예전엔 사내 데이터 학습시키겠다고 비싼 돈 들여서 파인튜닝(미세조정) 돌렸음. 이젠 그럴 필요 없이 그냥 관련 문서 수만 장 프롬프트에 쑤셔 넣고 질문하면 됨. (이걸 인컨텍스트 러닝이라고 부름)
RAG(검색 증강 생성) 최적화: 정보 검색하고 짜깁기하는 노가다가 사라짐. “작년 A프로젝트랑 이번 B프로젝트 비교해서 리포트 써와” 하고 데이터 뭉탱이로 던져주면 AI가 알아서 전문가처럼 뽑아줌. 체감상 혼자서 팀 단위 일량을 쳐내는 수준임.
뉴노멀 생존법
옛날 빅데이터 시절처럼 “우린 데이터 존나 많아” 하고 꺼드럭거리는 건 이제 안 통함.
방대한 맥락을 한 번에 꿰뚫어 보는 롱 컨텍스트 시대에는 딱 두 부류만 살아남음.
- 하드웨어 단에서 KV 캐시 연산 최적화와 HBM4 대역폭 병목을 뚫어내는 놈.
- 소프트웨어 단에서 프롬프트에 수백만 토큰의 데이터를 효율적으로 던져주는(RAG) 놈.
데이터를 모으는 게 아니라, 씹어 먹기 좋게 던져주고 하드웨어가 그걸 버텨내는 게 진짜 경쟁력이 된 세상임.
※ 본 글은 작성일 기준의 데이터와 개인적 분석을 바탕으로 작성되었으며, 산업과 기술에 대한 설명글입니다. 특정 자산에 대한 투자 권유나 재무적 조언이 아닙니다.