얼마 전 사무실에서 수백 페이지에 달하는 차세대 공정 장비 매뉴얼과 지난 3년간의 에러 로그 데이터를 앞에 두고 한참을 멍하니 있었습니다. 예전 같으면 이걸 일일이 검색해서 필요한 부분을 발췌하고, AI에게 물어볼 때도 ‘이 부분이 중요한데 요약해 줘’라며 쪼개서 넣어야 하는게 당연시 돼왔습니다. 그런데 Gemini 3.1 Pro 같은 최신 모델에 이 수만 줄의 데이터를 통째로 던져 넣었을 때, 단 몇 초 만에 제가 놓쳤던 변수 간의 상관관계를 짚어내는 것을 보고 소름이 돋더라구요. 8비트 게임기로 고전 게임을 하다가 갑자기 고사양 PC로 오픈월드 게임을 돌리는 느낌이랄까요? 현업에서 체감하는 ‘토큰 증가’는 단순한 기술 사양의 업그레이드가 아니라, 인간이 데이터를 다루는 패러다임 자체가 바뀌는 변곡점에 와 있다는 확신이 들었습니다.
토큰 500만 시대가 열리며 사라진 ‘정보의 파편화’
우리가 AI와 대화할 때 쓰는 단위인 토큰은 쉽게 말해 ‘언어의 조각’이라고 할 수 있죠. AI 초기 보급단계에서 Chat GPT가 기억할 수 있는 토큰이 수천 개 수준이었다면, 2026년 지금은 Gemini 3.1 Pro나 GPT-5, 클로드 5처럼 500만 개 이상의 토큰을 한 번에 처리하는 ‘롱 컨텍스트(Long Context)’ 모델들이 쏟아지고 있습니다. 500만 토큰이면 책 수백 권, 혹은 며칠 분량의 영상 데이터를 한꺼번에 집어넣을 수 있는 수준이죠. 이건 단순히 많이 읽는다는 걸 넘어, 수작업으로 매뉴얼을 뒤적거리는 시대가 완전히 끝났다는 의미이기도 합니다.
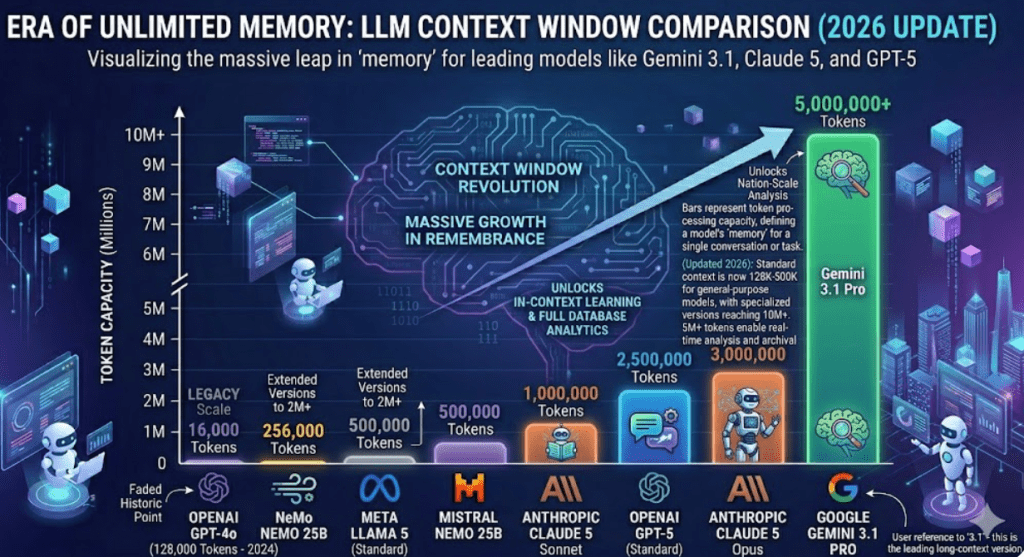
과거에는 AI가 앞서 했던 말을 금방 까먹거나, 긴 문서를 입력하면 뒷부분을 잘라먹는 일이 허다해서, “아 역시 AI는 무슨 한참 멀었구만” 했었는데, 이제는 ‘전체 맥락’을 한 번에 들여다 볼 수 있게 되었습니다. 이는 마치 돋보기를 들고 지도 여기저기를 살피던 사람이 헬기를 타고 지형 전체를 내려다보게 된 것과 같습니다. 데이터가 파편화되지 않고 하나의 거대한 맥락 속에서 해석되기 시작하면서, AI는 이제 단순한 비서가 아니라 복잡한 프로젝트를 함께 수행하는 ‘파트너’의 영역으로 진입했다는게 직접 체감이 되더라구요.
반도체 엔지니어가 보는 이면: 결국은 메모리 병목과의 전쟁
하지만 토큰이 늘어나는 걸 마냥 축제처럼 즐길 수만은 없는 게 솔직한 심정입니다. 반도체 설계와 공정단에서 보면, 토큰의 증가는 곧 연산량의 기하급수적인 폭증과 메모리 대역폭의 한계를 의미하거든요. 트랜스포머 아키텍처 기반의 모델들은 입력되는 토큰이 늘어날수록 필요한 연산 능력이 제곱 단위로 늘어나는 특성이 있습니다. 특히 ‘KV 캐시(Key-Value Cache)’라 불리는 일종의 중간 기억 장치의 용량이 커지면서, 이를 감당하기 위한 HBM4(고대역폭 메모리)의 수요는 상상을 초월하는 수준이 되었습니다.
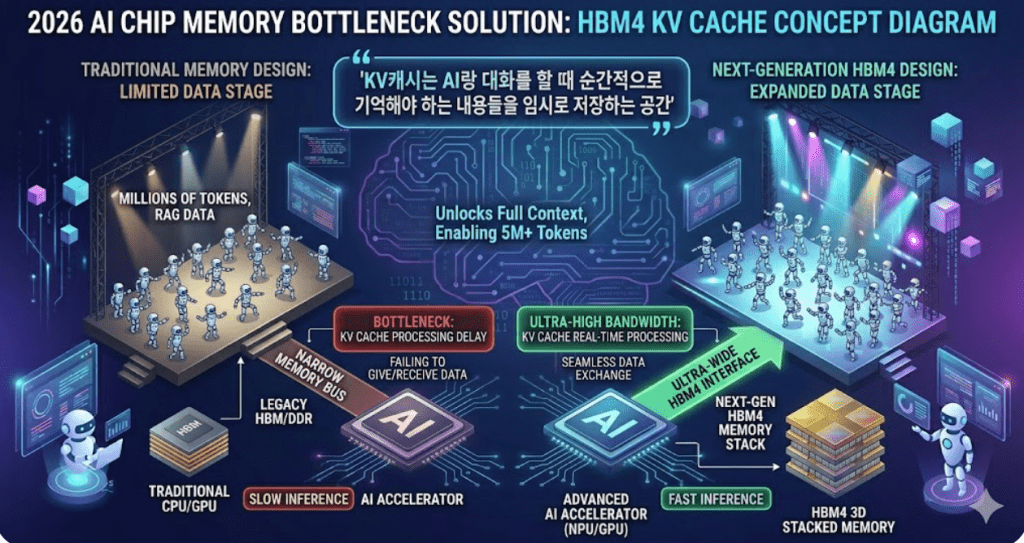
간단하게 말하자면, KV캐시는 AI랑 대화를 할 때 순간적으로 기억해야 하는 내용들을 임시로 저장하는 공간을 말합니다. 제가 현업에서 수율을 잡기 위해 고군분투하는 이유도 결국 여기에 있습니다. AI 모델이 더 똑똑해지려면 더 넓은 컨텍스트 윈도우가 필요하고, 이를 위해서는 더 빠르고 용량이 큰 메모리 반도체가 필수적입니다. 지금 시장에서 HBM4의 주도권을 누가 쥐느냐에 혈안이 되어 있는 이유도 바로 이 ‘토큰 경제’의 하부 구조를 선점하기 위해서입니다. 소프트웨어가 데이터를 마음대로 주고받으려면 그 무대인 하드웨어가 튼튼하고 넓어야 하는데 지금은 무대가 마음같지 않아서 데이터를 원하는 만큼 못 주고받고 있는 상황이니까요.
| 구분 | 2024년 (초기 AI) | 2026년 (현 시점) |
| 기본 토큰 용량 | 수만 개 수준 (단기 기억) | 500만 개 이상 (롱 컨텍스트) |
| 데이터 처리 | 문서를 쪼개서 입력 (파편화) | 수백 권의 책을 통째로 분석 |
| 메모리 기술 | HBM3 / HBM3E | HBM4 (KV 캐시 최적화) |
| 핵심 기술 | 단순 파인튜닝(Fine-tuning) | 고도화된 RAG 및 인컨텍스트 러닝 |
실제로 팹(Fab)에서 장비를 돌리다 보면 이 하드웨어의 한계가 뼈아프게 다가옵니다. 500만 토큰을 실시간으로 추론하기 위해 칩 내부에서 발생하는 열과 전력 소모를 보고 있으면, “소프트웨어의 진화를 하드웨어가 겨우겨우 따라가고 있구나”라는 생각이 듭니다. HBM4의 적층 수가 늘어날수록 공정 난이도는 점점 더 장난아니게 되는데, 이걸 해결하지 못하면 무한 토큰 시대의 속도는 반토막 날 수밖에 없습니다. 결국 이 전쟁은 누가 더 거대한 ‘데이터 무대’를 안정적으로 깔아주느냐의 싸움입니다.
토큰의 확장이 불러올 비즈니스의 지각변동: ‘딸깍’의 시대
앞으로 토큰의 증가는 검색 엔진의 종말과 ‘인컨텍스트 러닝(In-context Learning)’의 시대를 가속화할 겁니다. 기존에는 검색 엔진에서 정보를 찾아 나열했다면, 이제는 기업의 내부 기밀 데이터 수만 장을 AI에게 직접 학습시키지 않고도 토큰으로 입력해 실시간 분석을 요청할 수 있습니다. 굳이 무거운 미세 조정(Fine-tuning)을 거치지 않아도, 질문할 때 관련 자료를 뭉텅이로 던져주면 AI가 즉각적으로 해당 분야의 전문가처럼 답하는 ‘RAG(검색 증강 생성)’ 기술의 효율이 극대화되는 것이죠.
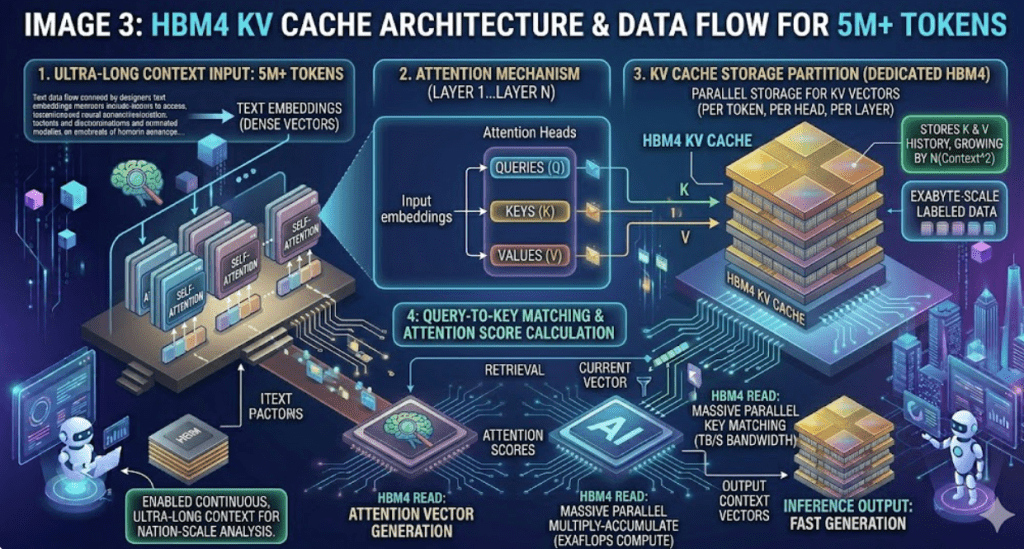
이게 진짜 체감이 큽니다. 원래같으면 대형 프로젝트로 여러사람이 붙어서 밤새 해야했던 일들이 AI 딸깍으로 쉽게 되어버리니까요. 마치 한명이 여러명의 팀을 꾸려서 일하는 느낌이라고 해야할까요? 또한, 이는 멀티모달(Multimodal)의 완성으로 이어집니다. 텍스트뿐만 아니라 장시간의 영상, 고해상도 이미지, 방대한 소스 코드 뭉치를 하나의 컨텍스트로 묶어 처리하게 되면 영화 제작, 소프트웨어 설계, 신약 개발 등 고도의 지적 노동 분야에서 생산성이 수십 배 이상 뛸 수밖에 없습니다.
결국 누가 더 많은 데이터를 ‘한 번에’ 이해하고 처리할 수 있는 무기를 가졌느냐가 국가와 기업의 경쟁력이 되는 시대가 온 것입니다. 이전에 제가 사회초년생때만 하더라도 빅데이터 전문가라는 것들이 많았는데, 과연 앞으로 어떻게 될 지 너무 궁금합니다. 이제는 단순히 데이터를 ‘많이 모으는’ 것보다, 그 방대한 맥락(Context)을 AI에게 어떻게 효율적으로 전달하고 하드웨어 병목을 어떻게 뚫어내느냐가 진짜 실력인 세상이 되어가는 것으로 보입니다. 뉴노멀.
💡 Insight Notes:
– 토큰 증가의 본질은 ‘단기 기억 상실증’의 치유입니다. 이제 AI는 파편화된 정보가 아닌 맥락 전체를 읽기 시작했으며, 이는 업무 효율의 비약적인 상승을 의미합니다.
– 반도체 업계에는 강력한 기회이자 위기입니다. 롱 컨텍스트 모델이 대세가 될수록 연산 최적화와 HBM4 등 메모리 대역폭 확보가 기업의 생존을 결정지을 것입니다.
※ 본 글은 작성일 기준의 데이터와 개인적 분석을 바탕으로 작성되었으며, 산업과 기술에 대한 설명글입니다. 특정 자산에 대한 투자 권유나 재무적 조언이 아닙니다.